The Draw Boy
The Jacquard loom, invented by Joseph Marie Jacquard in the early nineteenth century, was one of the first machines to be controlled by something resembling a stored program, namely a sequence of punched cards [2]. It wasn't a computer in the modern sense, but it demonstrated that a machine could perform complex work by following an external set of instructions, an idea that would echo through the history of computing.

A Local AI Model Setup for Apple Macs
In this post we’ll cover how to get multiple machine learning models running on Apple using Ollama, open-webui, and for image generation, stable-diffusion-webui.

Machine Learning for Engineers: Book List 2024
At the end of 2019, I posted a book list for engineers new to machine learning, to help develop basic knowledge of the fundamentals, organised into four groups: Machine Learning & Algorithms, Tools & Frameworks, Data Science & Analysis, and Companion Mathematics. This post provides an updated book list using the same groups, which have held up well. At the time the list covered 26 books, this iteration is more concise, covering 11 books. This time around 3 are new, and 3 have seen updated editions in the interim.
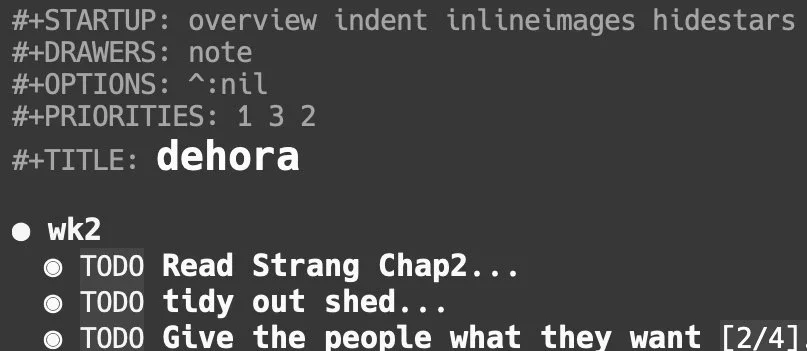
How I use Org Mode
I’ve mentioned more than once how effective I find org-mode as a productivity tool and organiser, without really explaining why. This post describes how I use org mode and why it’s been such an important application for well over a decade.
Some Books Were Read: 2021
Here are some notes on a few books I enjoyed and learned from in 2021, not all of which are books published that year.
Some books were read: 2020
Here are some notes on a few books I enjoyed and learned from in 2020, not all of which are books published that year.
Technical Prime: Enabling Engineering Decisions & Work
Technical Prime is a lightweight mechanism for enabling clarity of decisions and who’s working on what, that also affords learning and knowledge sharing.
Machine Learning for Engineers: Book List
In 2018, I posted a series of introductory, hands-on and more advanced book lists for engineers new to machine learning, to help develop a basic knowledge of machine learning fundamentals. This post provides an updated set of book recommendations reflecting changes since then, and an improved grouping for the books into mathematics, machine learning, data science, and programming tools.
Some books were read: 2019
Here are some notes on a few books I enjoyed and learned from in 2019, not all of which are books published that year.
Reasoning about Leverage in Engineering Organisations
Leverage is an important concept for an engineering organisation. When we are debating whether to standardise and on what, which technology tools and stacks to use, whether to add new technology, replace an old system with a new one, which programming languages to use and how many, under the surface we are ultimately talking about or around, the topic of leverage of technology.
Principles
A set of principles that have been meaningful and helpful to me. Nothing particularly originally, just that this set of approaches have worked as I’ve gone along. It took me a while to identify some of these, and in more than one (!) place, some time to figure out the would work and how to apply them 😀
MacBook Pro 2018 & Software Essentials
After 3 years, it was time to retire the old Macbook Pro 2015 and replace it with a 2018 touchbar model. Also some thoughts on software essentials since the last time I went through things, back in 2010 for a W500 Thinkpad, the last non-Mac laptop I used before switching.
Paper Reading 📄
A list of technical papers and memos that I want to read or re-read. I’d love to get recommendations on other papers especially from the last decade, that seem important or in some way foundational.
Thoughts for 2019
It's always interesting to look at the year ahead in technology, and so, some thoughts about 2019! These are less predictions, more extrapolations of what's already happening.
On Rust
Back in 2013, I started a series of posts on programming languages I found interesting. One of the languages I wanted to write about at that time was Rust. As often happens, life got in the way, and it’s only now that I’m coming round to a long overdue post. This is one of a series of posts on programming languages and you can read more about that here.