Tail Scale
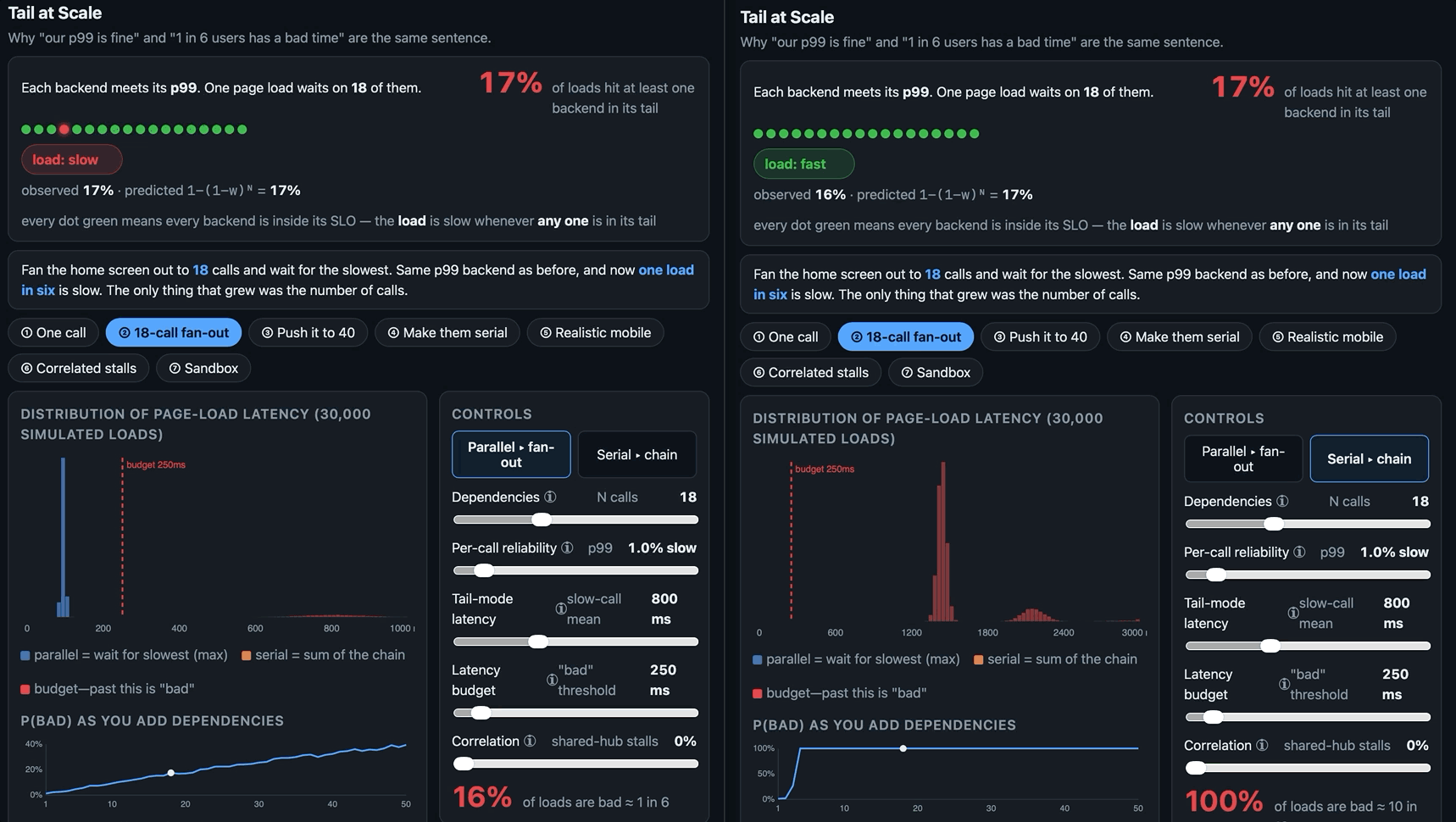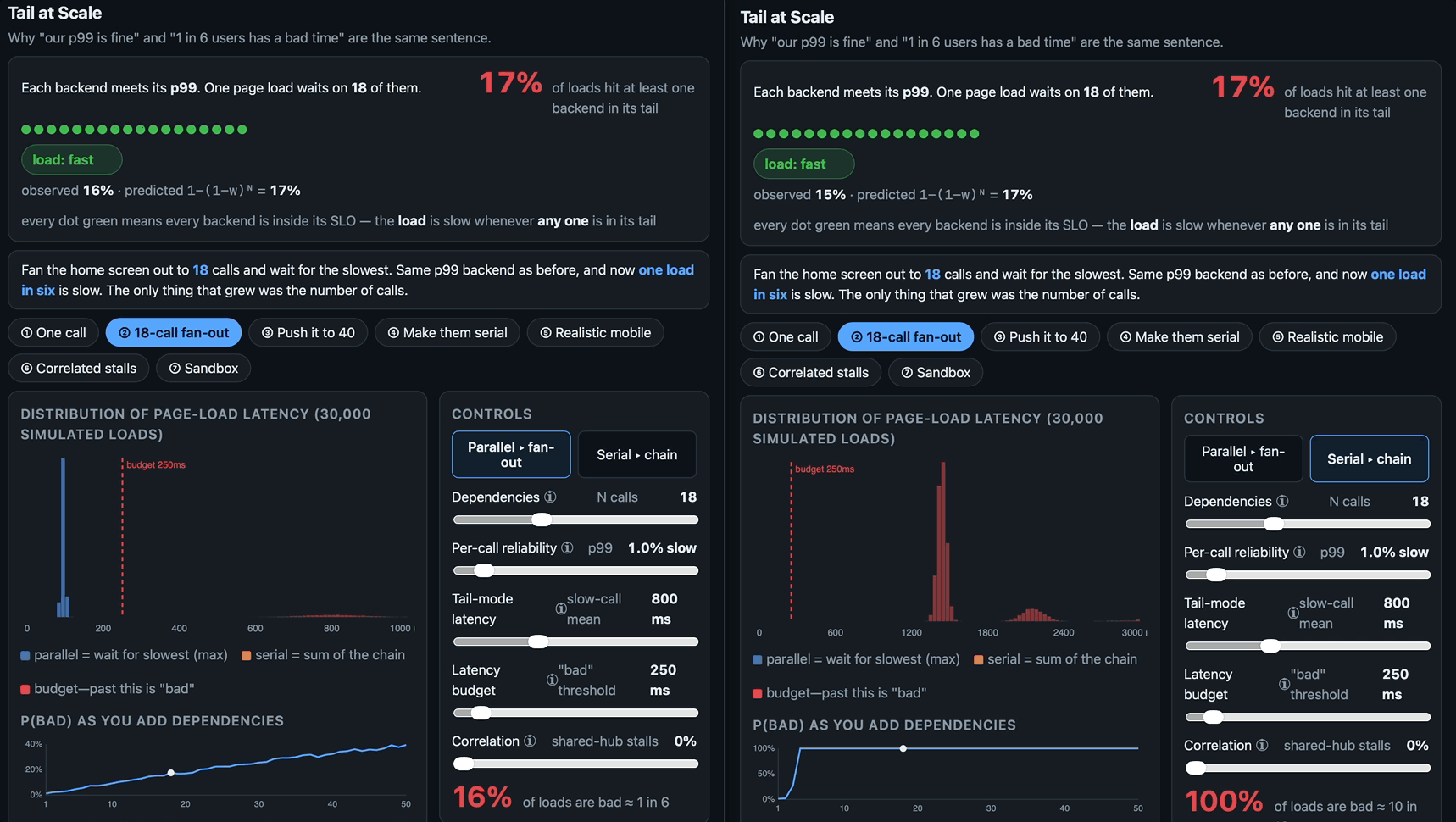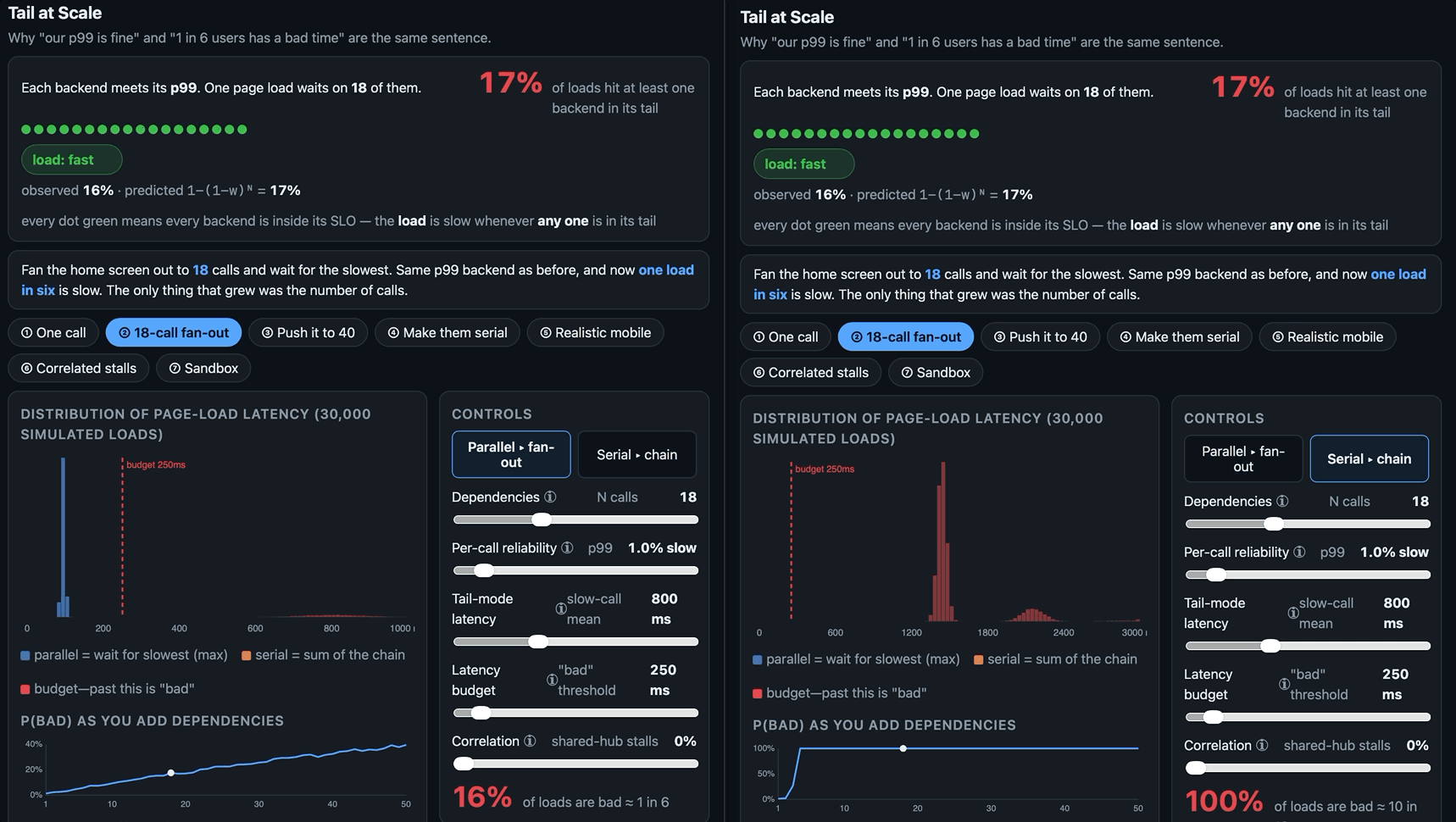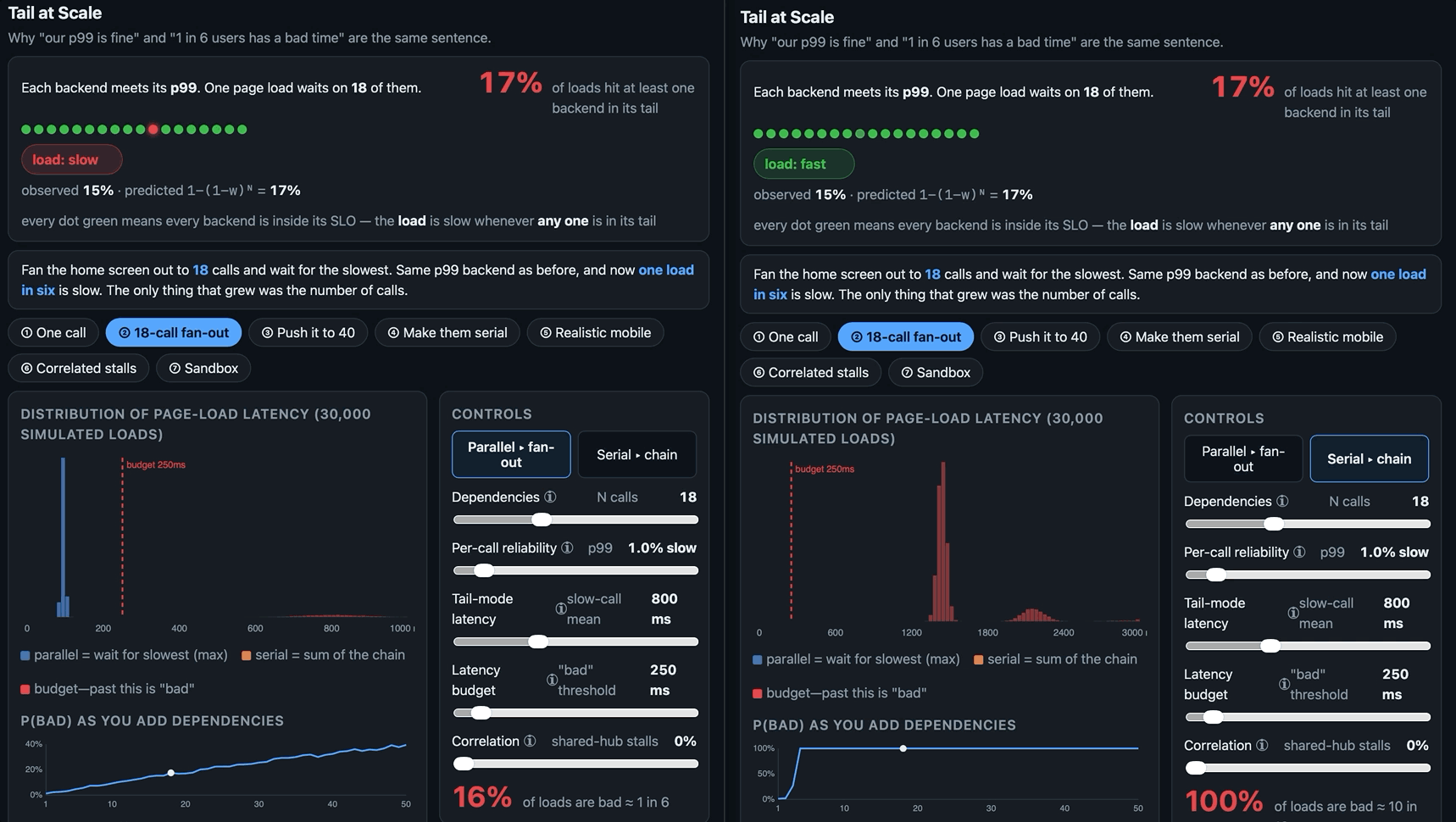
‘Our p99 is fine’ and ‘one user in six has a bad time’ are the same sentence. Herein a small browser tool to visualise the tail-at-scale effect: how a rare slow call stops being rare once a page waits on enough of them, and why every dashboard stays green while it happens.

Policywerk: From Tables to Imagination
Part 1 ended with a table with 192 entries, one per state-action pair, updated by a single rule. That post covered four foundational algorithms from 1957 to 1989: By then much of what is fundamental in reinforcement learning was in place—value functions, policies, temporal difference errors, the tension between exploration and exploitation, actors and critics.
The three lessons in this post cross that boundary. A neural network replaces the table. A probability distribution replaces the best value. An imagined world model replaces the real environment. Each step is a departure from what came before, and each one is built the same way: simple building blocks, and no frameworks.

Policywerk: Building Reinforcement Learning from First Principles
Most reinforcement learning code starts after the interesting part. Policywerk is a plain-Python Reinforcement Learning project that rebuilds Bellman, Actor-Critic, TD Learning, and Q-Learning from first principles, with tests, tiny environments, and animated visualizations that make the machinery visible.

Modelwerk: Beyond Transformers
The two most interesting models in the modelwerk series of lessons about neural networks turned out to be ones that came after the transformer. Not because they're better, but because they seek to answer the question 'what comes next?' in completely opposite ways. In this post we take a look at Mamba and Continuous Thought Machines.

Working with agents doesn't feel like flow
Working with agents doesn't feel like getting into flow to me. It feels more like a game loop: set direction, trigger action, watch what happens, evaluate, intervene, adjust, try again. Different kind of focus, different kind of reward. But fun.
Skilled Agents
I recently ran a security audit on a code base using a sub-agent and gave it a YAA (‘You Are A’) persona as a security engineer. It was good enough to want to keep around. This post describes a simple way to capture engineering personas and run them in Claude Code with a custom ‘/agent’ command.
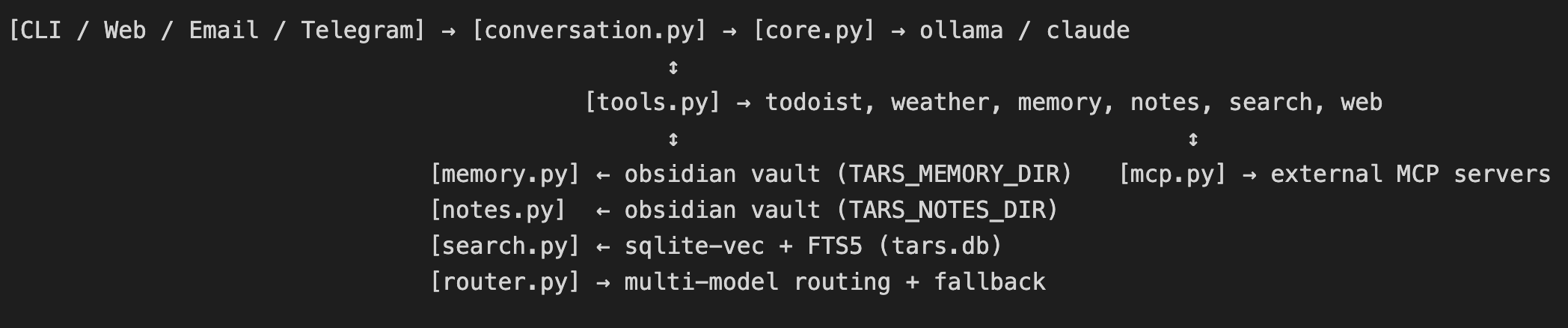
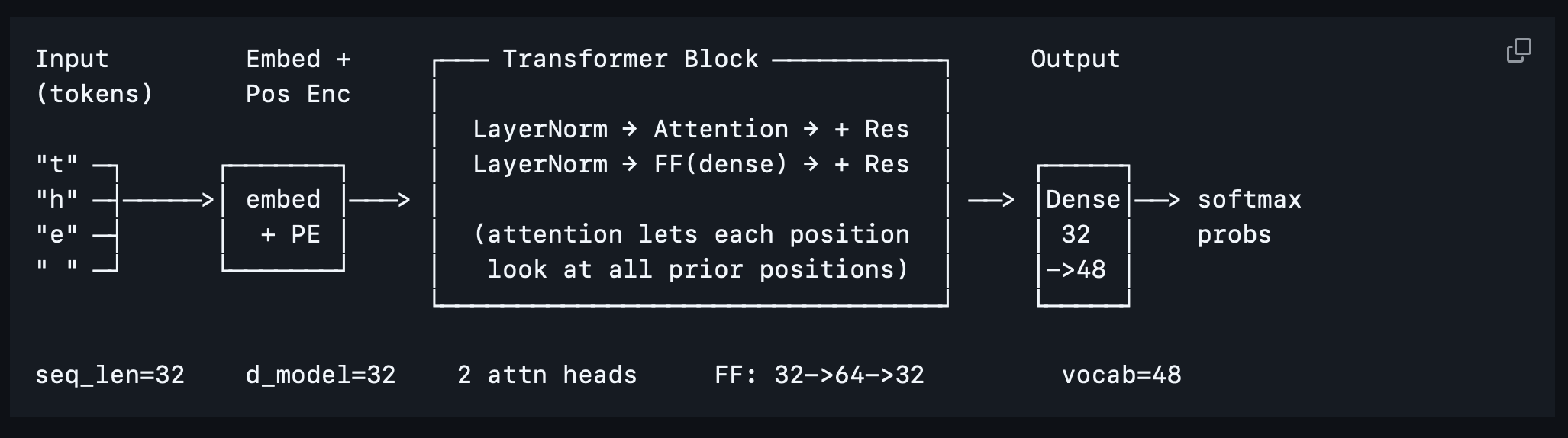
Agentic Engineering: Building Without Writing
tars is a personal AI assistant with CLI, Web UI, Email, and Telegram channels, persistent memory, hybrid search, integration with tools I used all the time. About 35 features, 14kloc of python and 600 tests all told. I didn't write any of it. The experience was different enough from traditional development, even from what we're doing with AI last year, to be worth writing up. The surprising part isn't that it worked or how capable the post-November Codex and Claude models now are. It's that the skills that mattered were different in a way that's going change the face of software development. And fwiw, I really enjoyed it.

Thoughts on Welcome to Gas Town
Some working thoughts on Steve Yegge’s Welcome to Gas Town. I read the essay a few times, then dug into the implementation to better understand how the system is structured. What follows is a mix of appreciation, architectural curiosity, and open questions about where this kind of agent harness might lead.
The Draw Boy
The Jacquard loom, invented by Joseph Marie Jacquard in the early nineteenth century, was one of the first machines to be controlled by something resembling a stored program, namely a sequence of punched cards [2]. It wasn't a computer in the modern sense, but it demonstrated that a machine could perform complex work by following an external set of instructions, an idea that would echo through the history of computing.

A Local AI Model Setup for Apple Macs
In this post we’ll cover how to get multiple machine learning models running on Apple using Ollama, open-webui, and for image generation, stable-diffusion-webui.

Machine Learning for Engineers: Book List 2024
At the end of 2019, I posted a book list for engineers new to machine learning, to help develop basic knowledge of the fundamentals, organised into four groups: Machine Learning & Algorithms, Tools & Frameworks, Data Science & Analysis, and Companion Mathematics. This post provides an updated book list using the same groups, which have held up well. At the time the list covered 26 books, this iteration is more concise, covering 11 books. This time around 3 are new, and 3 have seen updated editions in the interim.
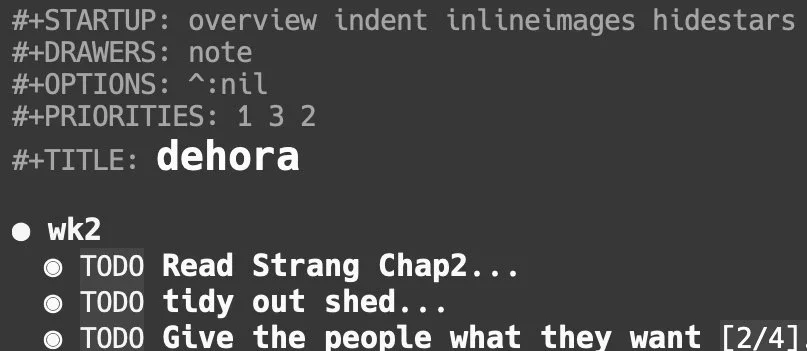
How I use Org Mode
I’ve mentioned more than once how effective I find org-mode as a productivity tool and organiser, without really explaining why. This post describes how I use org mode and why it’s been such an important application for well over a decade.
Some Books Were Read: 2021
Here are some notes on a few books I enjoyed and learned from in 2021, not all of which are books published that year.
Some books were read: 2020
Here are some notes on a few books I enjoyed and learned from in 2020, not all of which are books published that year.
Technical Prime: Enabling Engineering Decisions & Work
Technical Prime is a lightweight mechanism for enabling clarity of decisions and who’s working on what, that also affords learning and knowledge sharing.